


 問い合わせ
問い合わせ[サンプルあり]AWS Lambdaを使って検索結果をスクレイピング(Python 3.7)
目次
どうも、大学生アルバイトのカニミソです。
AWS上からスクレイピングを行う機会があったため、サンプルコードと実際に動作させるまでの手順についてまとめました。
なお、今回はスクレイピングする傍らLambda上で多数のデータをキューに入れ順番に処理していく、という状況を想定しています。
そのためAWS SQSをキュー、LambdaのトリガーとしてEventBridgeを使用しています。
仕組み(構成図)
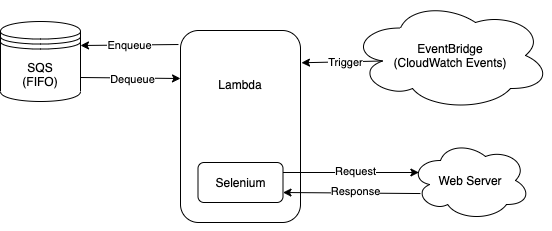
使用しているシステムとその関係
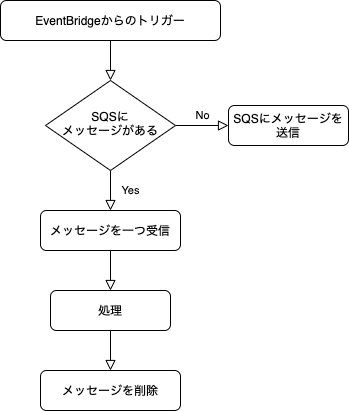
Lambda関数の大まかなフローチャート
仕組みの構成要素
AWS Lambdaとは
Lambdaとはクラウド上でコードの実行ができるサービスです。
ソースコードを書いてサーバー上に設置するだけでいいわけです。
利用料は従量課金制を言って使った分だけかかります。
レンタルサーバーとは違って全く使わなければ利用料はかからず、逆にたくさん利用すればそのぶん利用料がたくさんかかってしまします。
詳しくはこちら https://aws.amazon.com/jp/lambda/
AWS SQSとは
SQSとはクラウド上のキューイングサービスです。
キュー(Queue)とは待ち行列と呼ばれていて、データを入れる、取り出すという2つの操作だけが可能な簡素なデータベースと考えることができます。
AWS SQSではデータの順序が保持されるかどうかを選択することができます。
詳しくはこちら https://aws.amazon.com/jp/sqs/
今回はデータの順序を保つ必要があったためFIFO(first in first out)を選択しました。
Seleniumとは
Seleniumとはブラウザの操作を自動化するためのツールです。
ThoughtWorks社によってwebアプリのテストを自動化するという目的で開発され、現在ではwebサイトのクローリングや処理の自動化など様々な用途で使われています。
詳しくはこちら https://www.selenium.dev/history/
プログラムと各設定について
ここからはソースコードのサンプルと、実際に動作させるための設定についてまとめていきます。
キューを作成(SQS)
今回はキュータイプにFIFOを選びます。
設定の、コンテンツに基づく重複排除にチェックを入れておきましょう。
キューの名前はLambda関数のソースコード内で使用します。
Lambda関数の設定
ランタイムはPython3.7。
作成後は基本設定からタイムアウトとメモリを変更しておきます。それぞれ1分以上、384MB以上で動作を確認しています。そしてLambda関数からSQSを操作するために、自動生成されたLambda関数のロールにAmazonSQSFullAccessというポリシーを追加しておきます。
また、Seleniumを動作させるため後述するLayerを追加します。
そしてEventBridgeというトリガーを追加し、時間を設定して終わりです。
chromedriverとheadless-chromiumについて
SeleniumをLambda上で動作させるためにはchromedriverとheadless-chromiumを別途用意する必要があります。
この2つはソースコードに比べてサイズが大きいため、ソースコードとは別にLambda関数のLayerという場所にアップロードします。
LayerのランタイムはLambda関数と同じPython3.7。
Layerにアップロードされたファイルは /opt というディレクトリに配置されます。アップロード時の圧縮ファイルの中身がそのまま配置されるため、目的のファイルが /opt 直下にあるのかそうでないのかに注意しましょう。
※ 動作時のパーミッションについて
ファイルの圧縮、Layerへのアップロード作業を行った環境によってchromedriverとheadless-chromiumのパーミッションエラーが起きるようです。
現在確認している限りでは、MacOSではエラーが起きずWindowsではエラーが発生しました。
この記事で紹介するサンプルコードはWindowsでの作業を想定してLambda関数上でchromedriverとheadless-chromiumのパーミッションを書き換えています。
サンプルコード
lambda_function.py
from main import main
import shutil
import os
def lambda_handler(event, context):
shutil.copyfile("/opt/chrome/headless-chromium", "/tmp/headless-chromium")
shutil.copyfile("/opt/chrome/chromedriver", "/tmp/chromedriver")
os.chmod("/tmp/headless-chromium", 755)
os.chmod("/tmp/chromedriver", 755)
main()
os.remove("/tmp/headless-chromium")
os.remove("/tmp/chromedriver")
return event
main.py
import os
import sys,io
import json
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import boto3
def main():
sqs = boto3.resource('sqs')
queue_name = "example.fifo" // キューの名前
queue = sqs.get_queue_by_name(QueueName=queue_name)
messages = queue.receive_messages(MaxNumberOfMessages=1)
if len(messages) <= 0:
messages = [] // ここでキューに入れるデータを用意
for message in messages:
response = queue.send_message( MessageBody=(json.dumps(message)))
return
message = json.loads(messages[0].body)
messages[0].delete()
options = Options()
options.binary_location = '/tmp/headless-chromium'
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--single-process')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('/tmp/chromedriver', chrome_options=options)
url = "http://example.com" // スクレイピングしたいURL
driver.get(url);
// スクレイピング処理
driver.quit()
スクレイピングに関する注意
スクレイピングとは外部のサーバーからデータを収集し、加工、蓄積をすることです。
htmlを取得して抽出することが大半ですね。
実際にスクレイピングをするとなると、同じurlに何度もアクセスすることになります。
そのアクセス頻度が高ければアクセス先のサーバーに負荷をかけることになります。
こうしてアクセス先のサーバーがダウンしてしまうと、サーバーの管理者との間でトラブルに発展しかねません。
また、サーバーがダウンしてしまう前にアクセスをブロックされ、スクレイピングができなくなる可能性もあります。
安定してスクレイピングを行うために、スクレイピングする対象となるサーバーに負荷をかけないようアクセスの間隔は少なくとも1分以上あけましょう。








![[サンプルあり]カラーミーの共通テンプレートでグループの情報を表示(jQuery)](https://glic.co.jp/media/cache/article_list/uploads/0b/5a/0b5a62d823836b21059bbf69935638dc.jpg)
![[FAQ]WEBサイト制作・保守に関するよくある質問](https://glic.co.jp/media/cache/article_list/uploads/d0/46/d04609114f83f38d7053493e479df642.png)

